Wrestling with reference data stuck
in excel, csv files, or hard-coded?
It doesn't have to be this way...
Introducing TitanRDM dedicated Reference Data Management.
Powerful, lightweight, and developer-friendly Reference Data Management that lets users map, categorize, augment, bucketize, rank and organize data for data warehouses, data integration, data migration, regulatory reporting, config data management, metadata and even simple apps — across all platforms.
Use Cases
Data Warehousing
Map, categorize, augment, bucketize, rank and hierarchize data to support business intelligence and analytical reporting.

Data Migration
Let users map codes and values between legacy and new systems, ensuring timely input through testing cycles and reducing migration errors.
Data Integration
Harmonize data across multiple systems by managing consistent mappings and standardizations.

Config Data Management
Manage application configuration data through environments with consistency and versioning.

Regulatory & Compliance Reporting
Used to align internal organisational data to external regulatory reporting needs, groupings, classifications and formats.

Metadata
Capture the data that drives and configures data processes.
Not a spreadsheet. Not an MDM platform. Something better.
Intuitive Data Entry

User-friendly UI with configurable bulk upload and batch editing - ideal for users managing reference data efficiently.
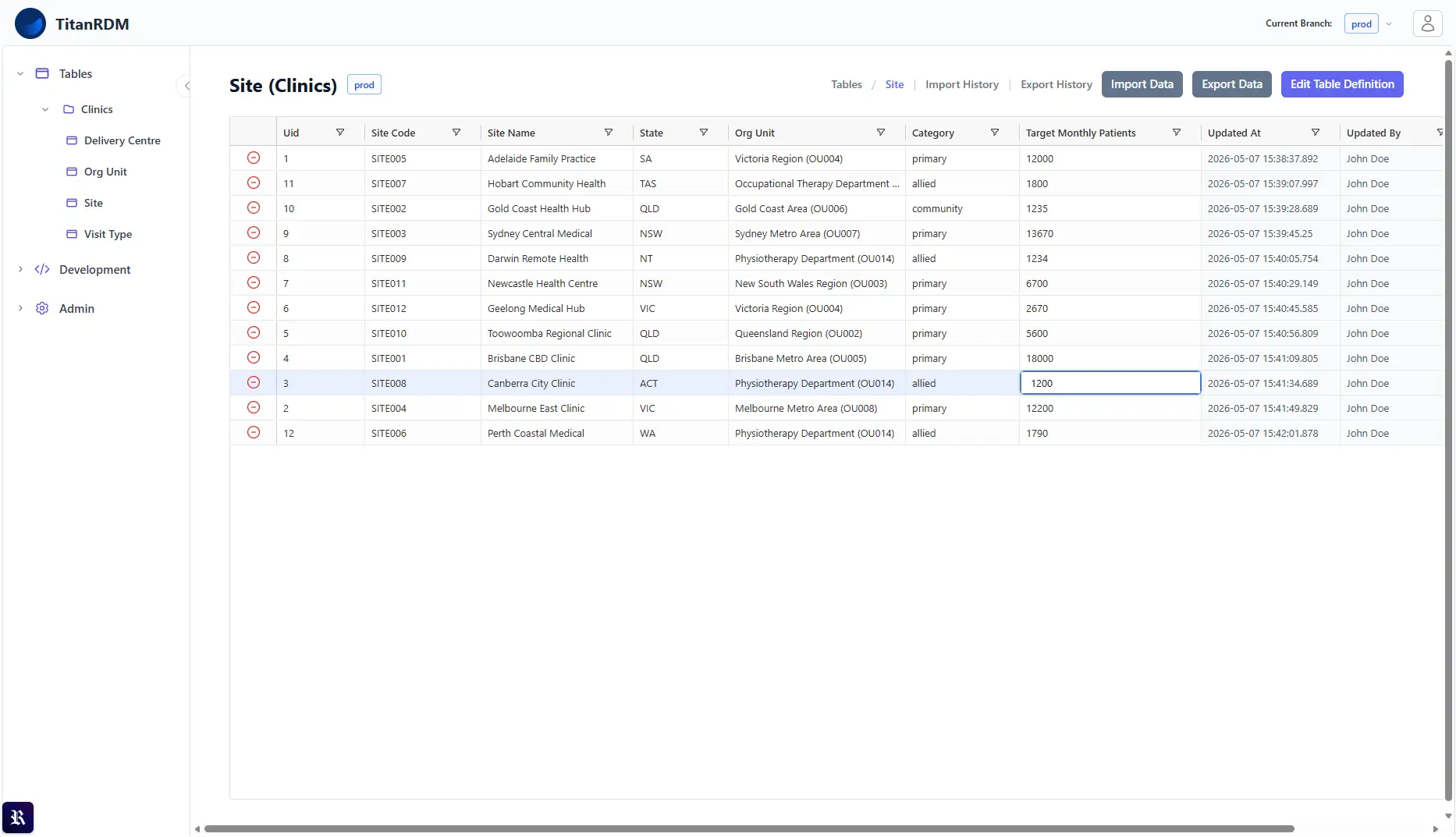
Intuitive, Excel-like data entry while maintaining data integrity. Use dropdowns to map to related data in other tables, or select from a list of valid values. Choose if users can create new rows, and what columns they can edit. Users can import, export and merge data to and from CSV or Excel files. Use the view's Search and Filters to narrow the data you are working on.
Click to enlarge
Deliver Reference Tables Fast
Click to enlarge
Let developers and super users create and manage reference tables without touching code.
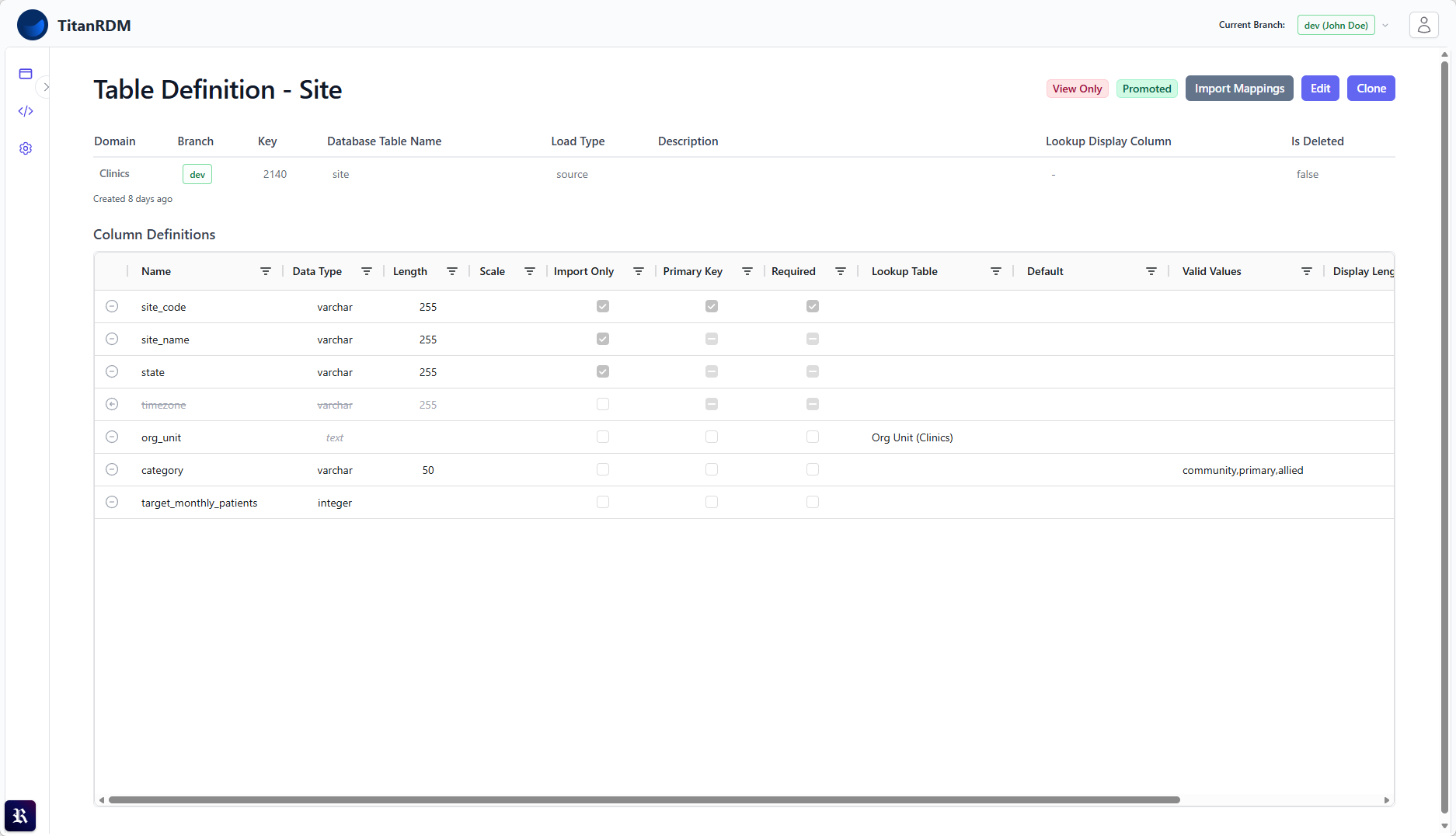
Define the table's fields, data types and primary keys. Define what columns are editable, and defaults. Define mappings to other tables, and validation rules like required fields and valid values. Tables are organised by Domain (Subject Area) with permissions per domain. You can even import the schema from a file.
Set up your first managed reference data table in under 10 minutes.
Free plan available.
Seamless Integration with Data Pipelines and Platforms
 Snowflake
Snowflake
 Databricks
Databricks
 BigQuery
BigQuery
 Redshift
Redshift
 Microsoft Fabric
Microsoft Fabric
 dbt
dbt
 Python
Python
 SQL
SQL
Fast and Lightweight Implementation No MDM Overhead
Traditional Master Data Managment (MDM) tools require a multi-year enterprise initiative, forcing businesses into complex golden record management, data stewardship models, and heavy governance workflows.
TitanRDM lets organizations quickly implement Reference Data Management for data warehouses, lakehouses, migration and integration projects without entangling them in MDM's complexities. TitanRDM can still form part of an MDM or data governance initiative but doesn't have too!
TitanRDM supports development best practices including branching and merging, allowing administrators and developers to work independently. You can create or modify RDM tables and deploy to production as needed, including pulling and merging data across environments if desired.
Why data teams choose TitanRDM
Built the way data engineers already work.
Branch your reference tables like code. Query them from any pipeline. Govern them without a multi-year platform rollout. TitanRDM fits into the stack you already have — it doesn't ask you to rebuild it.
Branch, Test, Promote
Manage reference table changes the same way you manage code. Create branches, test in dev, promote to staging and production with confidence.
Private Development Environments, shared Test and Production
Developers get their own private development environment where they can test their changes without impacting others. Once tested, changes can be promoted to shared test and production environments.
SDK for every Data Platform
Python SDK and REST APIs let you import and export reference data directly into your pipelines. Works with Azure, AWS, Databricks, Snowflake, and more, without changing your architecture.
Import from Anywhere, Export to Anywhere
Upload your existing csv files to get started in minutes. Export for downstream consumption, or to edit outside TitanRDM. Migration from Excel takes one afternoon, not a quarter.
No Vendor Lock-in
TitanRDM works across AWS, Azure, GCP, and on-premise environments. It fits into your existing stack without replacing it. Connect it to whatever data platform you're already using.
Audit Trails without MDM Complexity
Row-level audit trails tied to users and imports without a multi-year MDM implementation. Know what changed and who changed it.
You've tried the workarounds. Here's why they fall short.
| Spreadsheets / CSV | dbt seed files | MDM Platforms | TitanRDM | |
|---|---|---|---|---|
| Setup time | Minutes | Minutes | 6–18 months | Hours |
| Business user editable | ✓ | ✗ | Partial | ✓ |
| API / SDK access | ✗ | Via dbt only | ✓ (heavy) | ✓ |
| Audit trail | ✗ | Git history only | ✓ | ✓ |
| Environment promotion | ✗ | ✗ | ✓ | ✓ |
| Platform independent | ✓ | dbt only | Usually not | ✓ |
| Governance overhead | None | None | Very high | Lightweight |
| Cost | Free | Free | $$$$ | Free tier + paid |
Your lookup tables deserve better than a shared spreadsheet.
Set up your first managed reference data table in under 10 minutes.
Free plan available. No credit card. No sales call.